pandas.columns、get_dummies等用法
发布日期:2025-05-01 20:36:19
浏览次数:2
分类:技术文章
本文共 717 字,大约阅读时间需要 2 分钟。
columns
import pandas as pddf = pd.DataFrame([ # (3,2) ['green' , 'A'], ['red' , 'B'], ['blue' , 'A']]) df.columns = ['color', 'grade'] # 相当于每一列的titledf
执行结果:

get_dummies
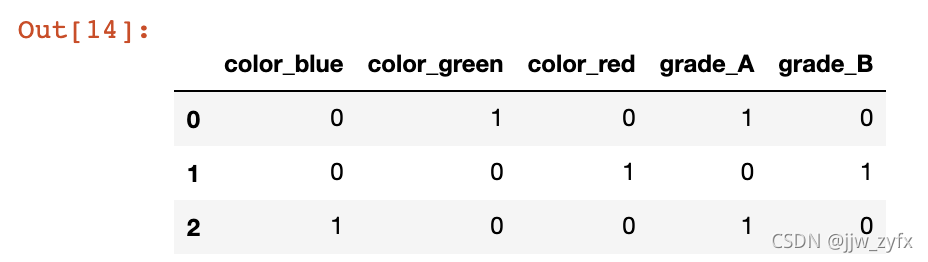
# 就是将每一列中的元素进行分类,然后每一行中如果有此类就写1,没有就写0pd.get_dummies(df)
执行结果:
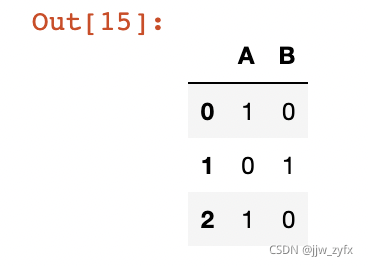
pd.get_dummies(df.grade) # 指定为某一列分类
执行结果:
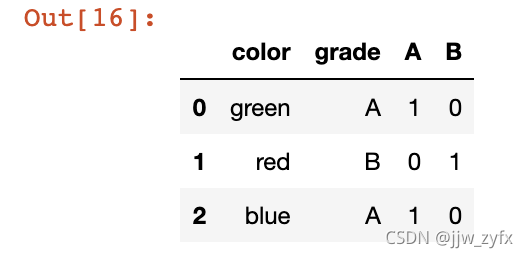
df.join(pd.get_dummies(df.grade)) # 将某一列的分类添加到之前的里边
dummy_na的用法
import numpy as npimport pandas as pddf = pd.DataFrame([ # (3,2) ['green' , 'A'], ['red' , 'B'], ['yello' , np.nan], ['blue' , 'A']]) df.columns = ['color', 'grade'] # 相当于每一列的titledf
输出结果:

pd.get_dummies(df)
输出结果:
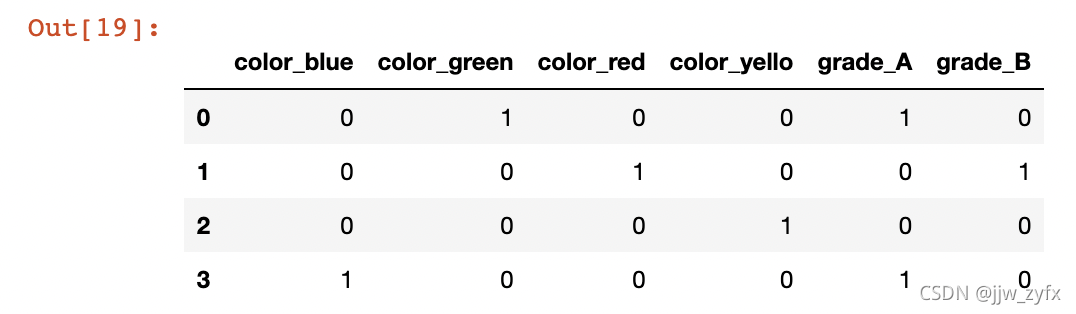
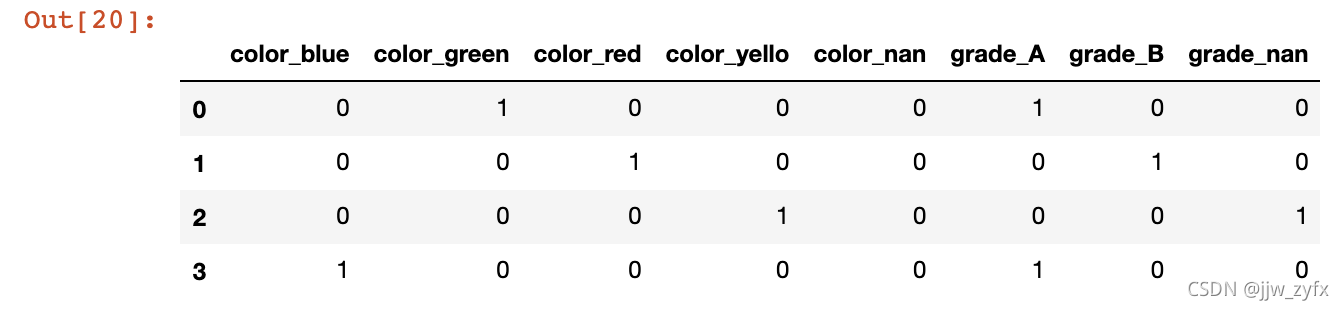
pd.get_dummies(df, dummy_na=True) # 从输出结果来看就是将每一列多添加一个nan列
发表评论
最新留言
表示我来过!
[***.240.166.169]2025年04月19日 00时56分39秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Pandas - 有条件的删除重复项
2025-05-01
pandas :to_excel() float_format
2025-05-01
pandas :加入有条件的数据框
2025-05-01
Pandas DataFrame多索引透视表-删除空头和轴行
2025-05-01
Pandas matplotlib 无法显示中文
2025-05-01
Pandas Plots:周末的单独颜色,x 轴上漂亮的打印时间
2025-05-01
Pandas 使用指南
2025-05-01
Passport 授权码模式
2025-05-01
pdf从结构新建书签_在PDF文件中怎样创建书签
2025-05-01
Perl6 必应抓取(1):测试版代码
2025-05-02
Phoenix简介_安装部署_以及连接使用---大数据之Hbase工作笔记0035
2025-05-02
PhotoManage
2025-05-02
PhotoPrism:这款获得35.8K星的AI照片管理神器你值得拥有
2025-05-02
photoshop 安装问题
2025-05-02
Photoshop2021 出现不可恢复的问题,即将退出
2025-05-02
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 461014757 位访客
访问时间: 2025-05-02 03:35:03
访问IP: 3.14.251.87
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版